2019-08-07 15:36:09
目前,在APP的海外广告推量领域,如何进行高质量的推量投放以达到用户持续性增长的目标,是行业的普遍痛点。

每个国家的CPI不同,到底哪些国家值得推量?
同样的国家,为什么不同推量日期的用户次日留存率差异如此之大?
不同类型(工具类,游戏类等等)的APP推量变现效果截然不同,如何找到一套适合自己APP类型的推量评估方法?
每次的推量就像一场场的丢硬币,赚不知其所以然,亏亦不知其所以然。
因此,如何有效利用LTV预测模型实现用户增长,已然成为当前APP开发者和广告主关注的重中之重。
下面将以DotC United Group(DUG)的LTV预测模型为例,为大家详细解读LTV的重要性及其应用。

众所周知,诸如此类的问题通过特定时间点(7,14,30,60日)的LTV和其对应的CPI通常能得到很好的解答。但如果等拿到14、30、60天的真实LTV再去做推量决策,通过长时间的等待之后再决策,这是商业盈利所不能接受的。
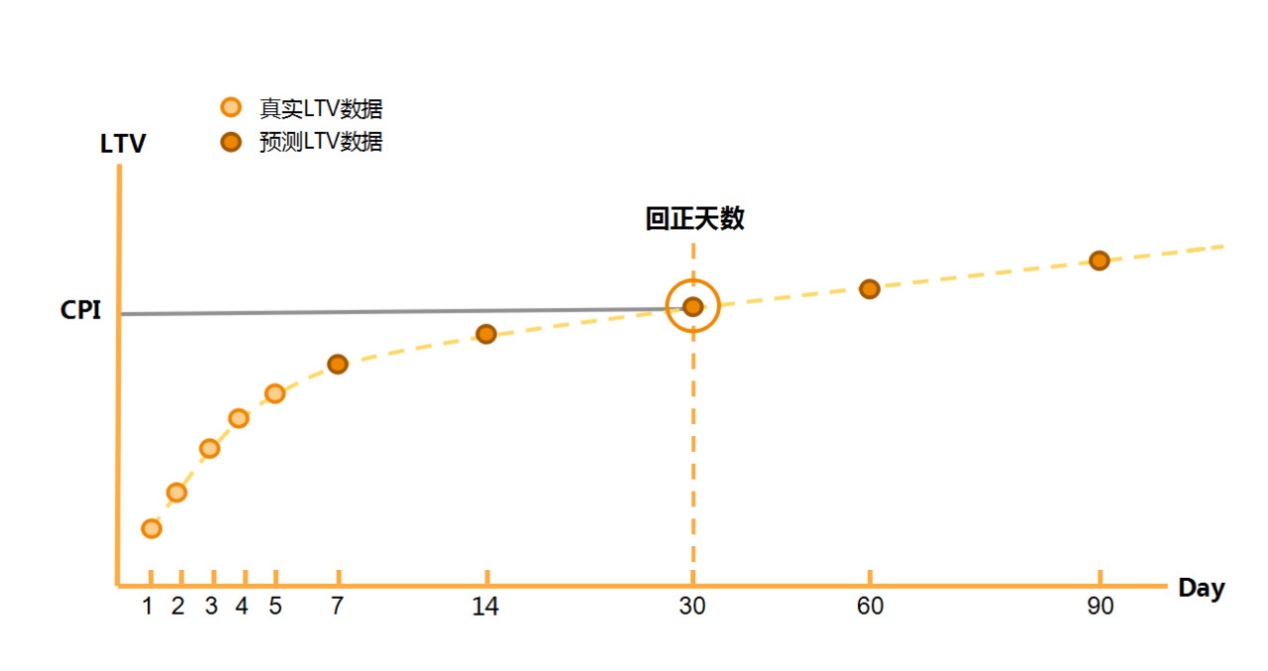
所以,通过我们的LTV预测模型,可以在推量后的第5天,得到一个预估的LTV14、LTV30、LTV60的数值,并且这个数值只要符合商业上的误差容忍度,我们便可以“预知未来”,更快更好地制定下一步的推量策略。
第一版LTV预测算法
起初,我们使用的第一版LTV预测算法,通过使用特定拟合函数对用户留存率进行预测,计算1-7天的ARPU乘以累加留存率预测产生的收入。然而结合我们的商业场景,第一版LTV算法实际上线后,我们发现前期留存率的预测是相对准确的,虽然存在拖尾过早的现象,预测精度还可以接受,但是由于ARPU曲线是前期处于高位的,中后期快速下降,仅用前期高位的ARPU进行计算,会造成预测收入远高于真实收入,过于乐观地以较高的CPI进行买量,导致最后真实ROI严重低于预测ROI,甚至入不敷出。
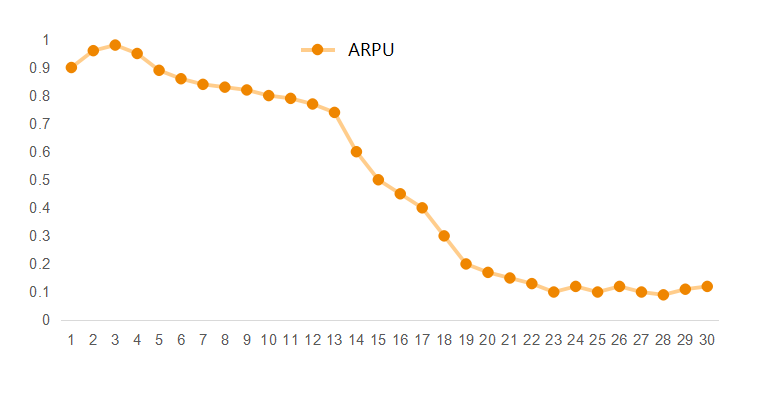
同时,第一版LTV预测算法的初衷是针对那些APP内用户行为丰富并且内购收入占比较高的场景,对内购收入平稳的APP更友好,但是,我们以广告流量变现为主的APP,因为业务场景的差异,在使用第一版的LTV算法时会产生很大的预测误差。
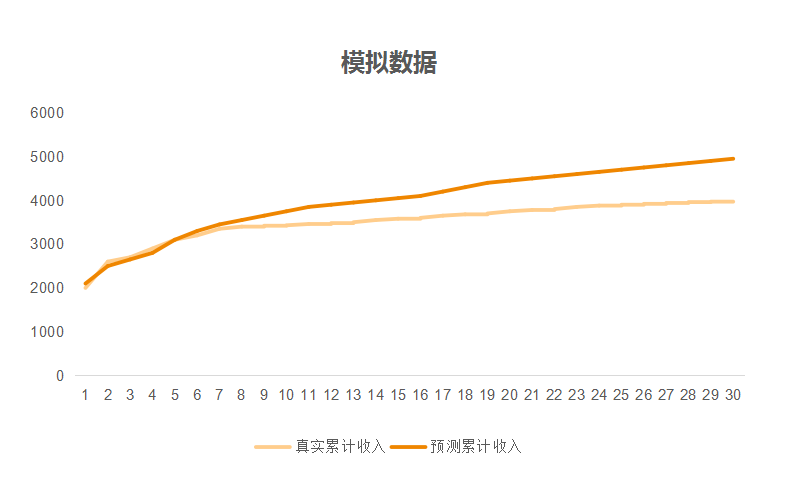
为了避免这种情况并且找到适合当前商业场景的算法,我们取其精华,去其糟粕,对第一版LTV预测算法进行改进提升,创建了第二版新的LTV预测算法。
第二版LTV预测算法
第二版创建了两种模型,最后需对两个模型的预测结果进行叠加得到预测结果。
一种模型是基于累计收入的非线性回归,另一种模型是基于留存率、收入和用户打点数据的预测模型,沿用了GBDT算法的核心思想,对预测结果的误差进行多轮迭代以提升预测精度。
没有最好的万能的模型算法,只有最适合自身业态和商业场景的模型算法。最终,得到的新LTV模型相较于第一版的LTV模型,预测的平均绝对误差率从30%降低到9.5%,更符合广告流量变现的商业场景。

在我们的新LTV预测模型自动化部署部分,输入数据是动态预测,需要每批推量用户后至少5天的真实留存率和留存用户行为数据,所谓动态预测,即首次预测当日需要至少5天的真实数据,之后的每一天都会结合最新拥有的真实数据进行再次修正之前的预测结果,根据算法的信息增益准则,拥有更多天数的真实数据带来的是更精准的预测结果。
LTV预测模型的输出数据是每批推量用户第7、14、30、60天的预测LTV。每批推量用户的细分维度定义是特定日期( date )的特定APP( app_id )的特定国家( Geo ),这样输出的预测结果的颗粒度针对买量批次的多样性可以保证较好的精确度,后续也可以将预测结果进一步聚合到APP或者国家的维度,满足商业上宏观数据指标的需求。
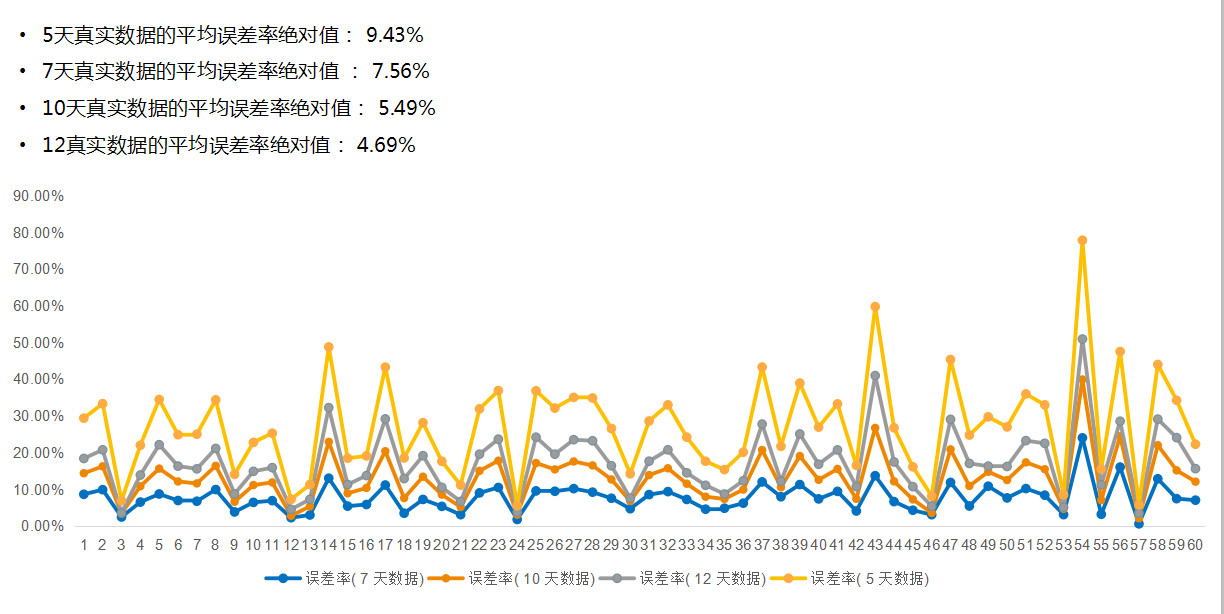
根据大数据的统计,特定一批推量用户在前30天内产生的Revenue大约会占其90天Revenue的80%-90%。所以,我们以第30天的LTV预测值和真实第30天的LTV,计算它们的绝对值误差率,作为评估预测模型的唯一指标。
我们选用半个月内所有投放的300多批次的推量用户样本的5天留存率和用户行为数据作为模型的Test Set,覆盖100+个海外国家,超过10种分类的30+款的APP,分别对每批推量用户的30天LTV进行预测。
经过测试集的验证,全样本平均绝对误差率在9.50%,全样本最大绝对误差率18%,并且,较高的误差率预测样本主要集中在非主流国家样本和DNU相对少的推量用户样本,在DNU >= 10K的样本,绝对误差率更小并且它的波动更加平稳。
同时,85%的样本预测结果属于负误差的保守预测,即预测的LTV小于真实的LTV。这样预测的好处是,在推量投放时,公司的投放推量行为会相对地更加稳健,可能会错过那些小赚的推量机会,更重要的是能够规避损失的投放(小亏or大亏),降低推量行为带来的损失波动。
对于新上线的APP来说,前期不计成本的推量以达到用户快速增长的目的已经成为行业共识。
新APP前期的用户池确实需要快速积累,但是很快进入运营的中期,前期积累的用户池不断自然流失,那时则需要LTV预测模型的预测结果,更加“未卜先知”地制定推量策略,完成对用户池的高质量持续性增长和沉淀。
LTV预测功能上线
近日,DotC United Group(DUG)LTV算法模型预测功能全新上线,大家只需简单输入相关数值,即可查询LTV预测结果!
使用下方链接,可利用DUG算法模型预测LTV
http://ltv.dotcunited.com//webview/ltv